Getting Started: Pipelines
What Does This Article Cover?
- What is a Pipeline?
- Pipeline considerations
- Common Pipeline Use Cases
- Building Pipelines
- Other Related Material
What is a Pipeline?
A Pipeline is comprised of Stages that can be combined to buffer, transform, and restructure data from any Source before being written to Target(s). When data is written to the Pipeline, the pipeline propagates the value and accompanying metadata to each pipeline stage according to Stage Layout. Each stage executes against the event and transmits the event to the next stage(s).
Pipeline considerations
- Consider the consuming system’s requirements of incoming data. Common questions one might ask include: does it require a flattened JSON object, does it require an array of buffered data, and does it require a specific file format?
- When building new Pipelines, consider enabling the “Track Events” setting within the Pipeline Start stage to see additional details from each Stage. “Track Events” adds to the compute resource load,so it should only be enabled when troubleshooting.
- When testing new Stages, consider adding a Write New Stage to output each stage results to a test topic within the Intelligence Hub’s local broker.
- When a Pipeline is ready for incoming data, be sure to add the Pipeline as a Flow target.
Common Pipeline Use Cases
Machine Learning Challenge:
For machine learning use cases, consuming systems require large data sets over a period of time to establish a baseline. ML consuming systems may have requirements, such as rigid file format requirements necessary to deliver data to cloud storage endpoints like Azure Blob Storage or AWS S3 Buckets. Meeting these needs can be complex for the data engineer.
Machine Learning Solution:
Consider building a Pipeline with Stages, such as Time / Size buffers, compression, and formatting stages before writing the data to the cloud target.
Descriptive Analytic Challenge:
For visualizing data in SCADA or BI systems, complex JSON objects often cannot be natively utilized. Perhaps you have a nested JSON object that has key metrics you need to associate within the visualization layer.
Descriptive Analytic Solution:
Consider building a Pipeline with Stages such as Flatten or Breakup transforms. This will ensure data is delivered to the consuming system in a ready-to-use format.
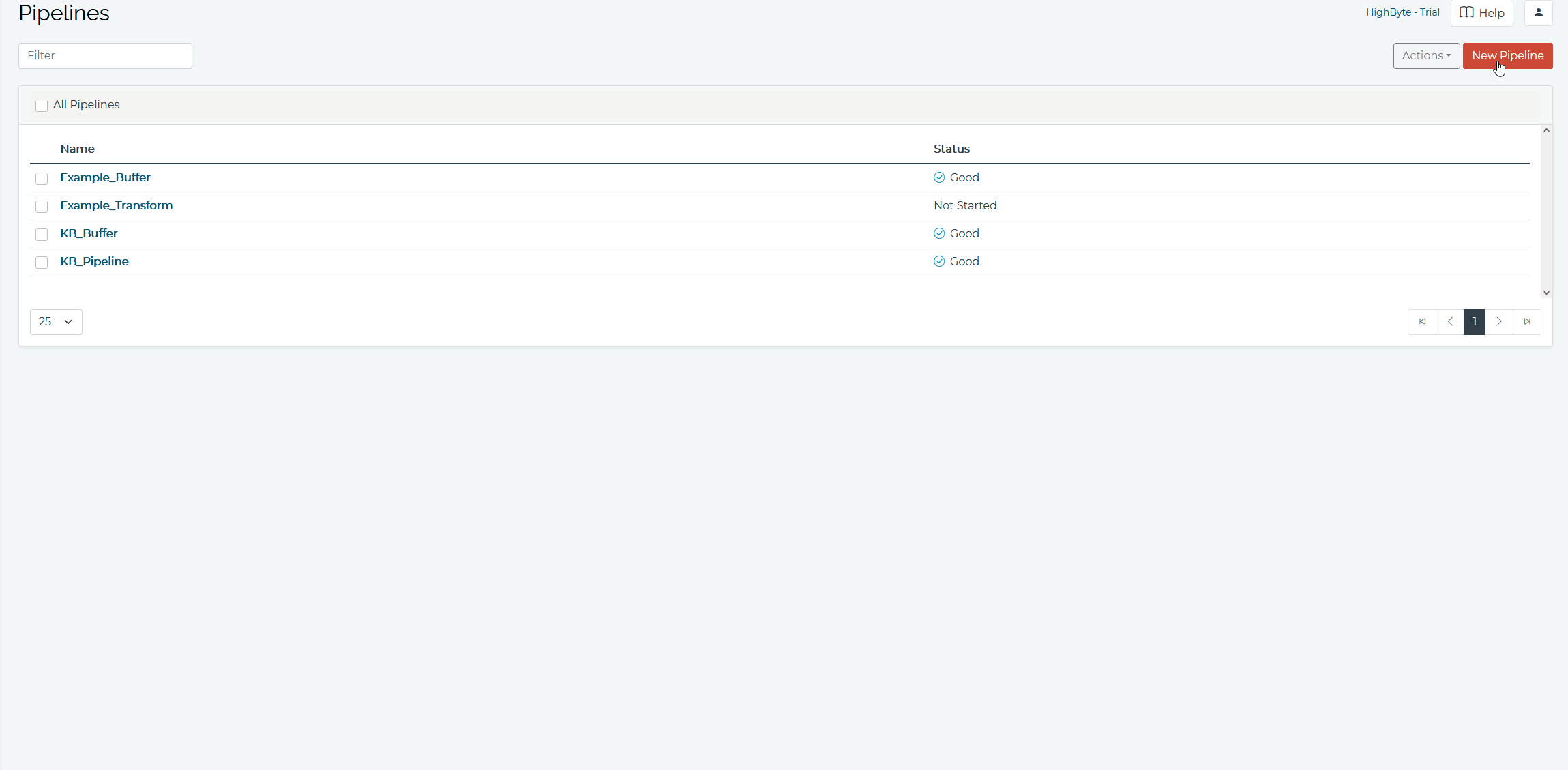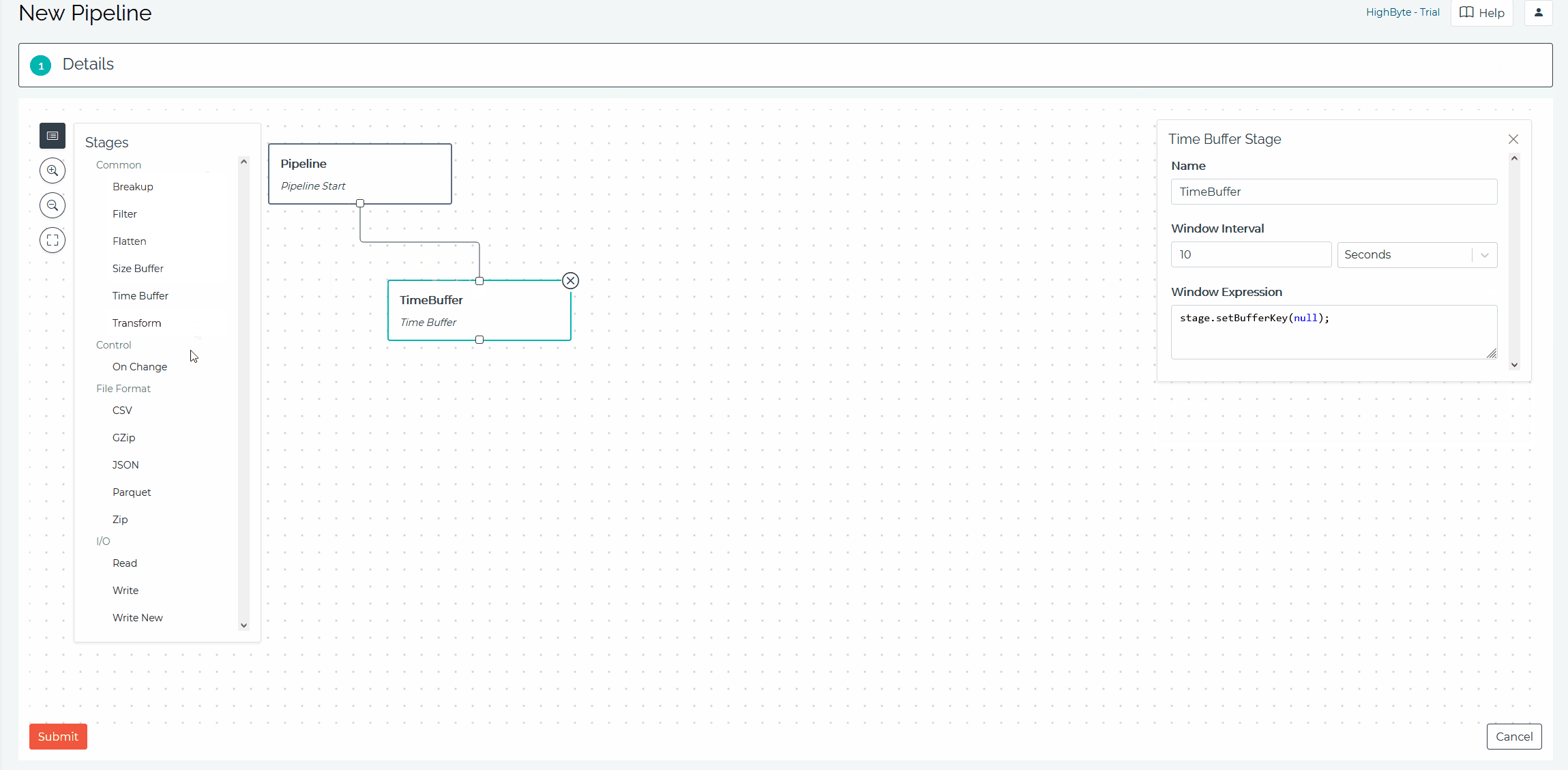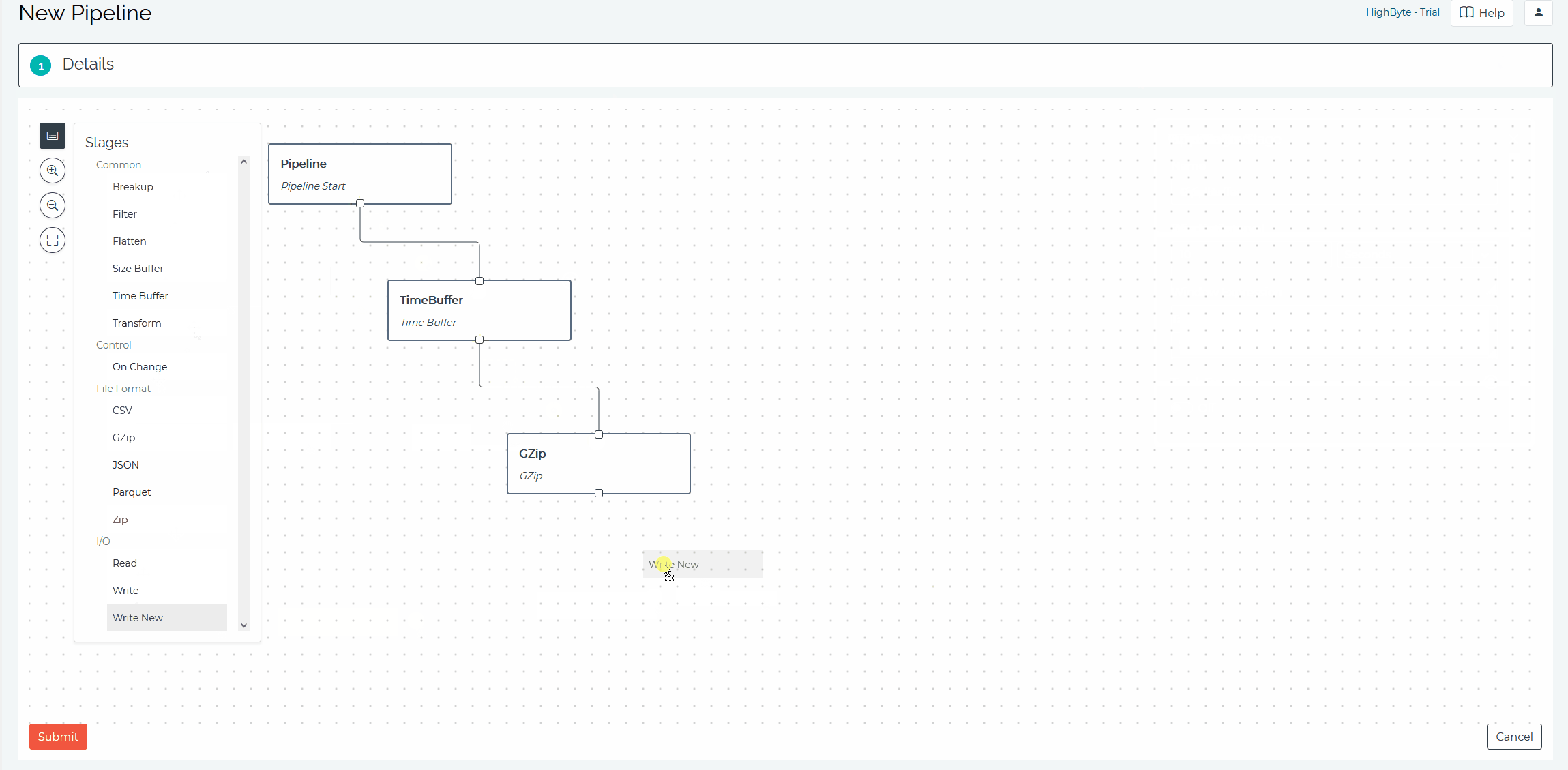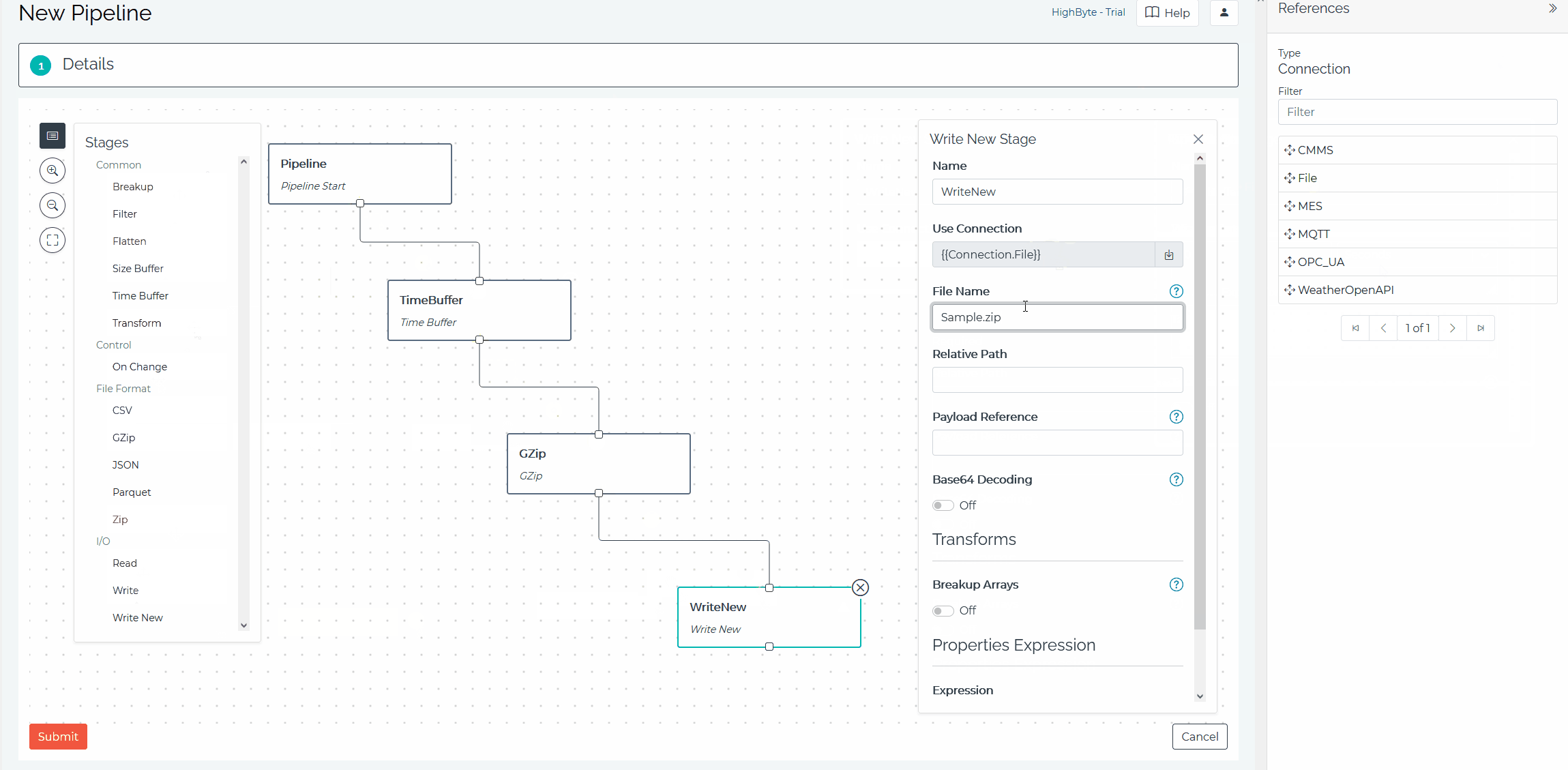
Building Pipelines:
Other Related Material:
- Tutorials to be added
- Pipeline User Guide